Used Python to Collect Data from any Website
There are moments while working when you realize that you may need a large amount of data in a short amount of time. These could be instances when your boss or customer wants a specific set of information from a specific website. Maybe they want you to collect over a thousand pieces of information or data from said website. So what do you do?
One option could be to check out this website and manually type in every single piece of information requested. Or better yet, you could make Python do all the heavy lifting for you!
Utilizing one of Python’s most useful libraries, BeautifulSoup, we can collect most data displayed on any website by writing some relatively simple code. This action is called Web Scraping. In the next few parts, we will be learning and explaining the basics of BeautifulSoup and how it can be used to collect data from almost any website.
The Challenge
In order to learn how to use BeautifulSoup, we must first have a reason to use it. Let’s say that hypothetically, you have a customer that is looking for quotes from famous people. They want to have a new quote every week for the next year. They’ve tasked us with the job to present them with at least fifty-two quotes and their respective authors.
Website to Scrape
We can probably just go to any website to find these quotes but we will be using this website for the list of quotes. Now our customer wants these quotes formatted into a simple spreadsheet. So now we have the choice of either typing out fifty-two quotes and their respective authors in a spreadsheet or we can use Python and BeautifulSoup to do all of that for us. So for the sake of time and simplicity, we would rather go with Python and BeautifulSoup.
Starting BeautifulSoup
Let’s begin with opening up any IDE that you prefer but we will be using Jupyter Notebook. (The Github code for all of this will be available at the end of the article).
Importing Python Libraries
We will start by importing the libraries needed for BeautifulSoup:
from bs4 import BeautifulSoup as bs
import pandas as pd
pd.set_option(‘display.max_colwidth’, 500)
import time
import requests
import random
Accessing the Website
Next, we’ll have to actually access the website for BeautifulSoup to parse by running the following code:
page = requests.get(“http://quotes.toscrape.com/“)page# <Response [200]>
This returns a response status code letting us know if the request has been successfully completed. Here we are looking for Response [200] meaning that we have successfully reached the website.
Parsing the Website
Here we will be parsing the website using BeautifulSoup.
soup = bs(page.content)soup
Running this code will return what looks like a printed text document in HTML code that looks like this:

We can navigate through the above, parsed document using BeautifulSoup.
Navigating the Soup
Now we will need to find the exact thing we are looking for in the parsed HTML document. Let’s start by finding the quotes.
An easy way to find what we are looking for is by:
- Going to the webpage and finding the desired piece of information (in our case, the quotes).
- Highlight that piece of information (the quote)
- Right click it and select Inspect
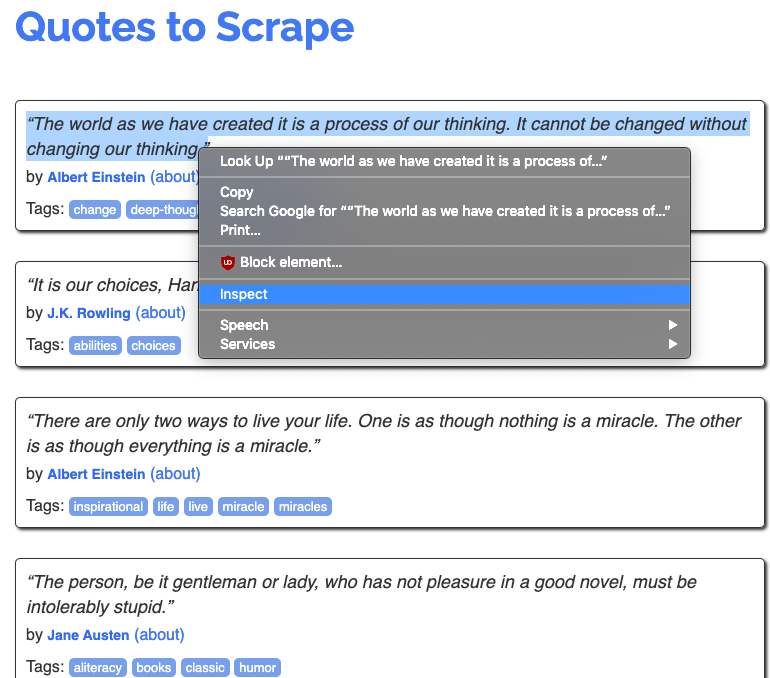
This will bring up a new window that look like this:
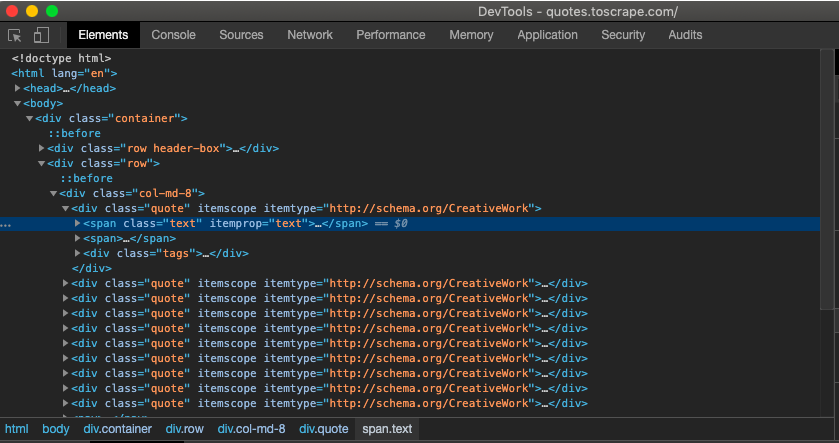
The highlighted section is where we will find the quote we are looking for. Just click the arrow on the left of the highlighted section to see the quote in the code.
HTML Information for Navigation
Based on the HTML code we see highlighted we can use that information to navigate the soup. We will be using the .find_all() attribute in our own code to potentially find the quotes we are looking for. This attribute will be able to return to us the desired line (or lines) of code based on whatever arguments we give it. Since we can see that the HTML code for the quote contains class=“text”, we can use that in our BeautifulSoup code:
soup.find_all(class_=’text’)
Running this code will return the following results:

From this we can see that we are able to successfully locate and retrieve the code and text containing the quotes needed.
In order to only retrieve the text and exclude the unnecessary code, we will have to use the .text attribute in each result. To do so, we will have iterate through the list using a “for” loop:
quotes = [i.text for i in soup.find_all(class_=’text’)]quotes
This will give us the list of quotes without their respective HTML code:

Now we know how we can access the quotes within the website and retrieve them for our purposes. Repeat the steps mentioned before to retrieve the author names for each quote as well:
authors = [i.text for i in soup.find_all(class_=’author’)]
Accessing Multiple Pages
Now that we know how to retrieve data from a specific webpage, we can move on to the data from the next set of pages. As we can see from the website, all the quotes are not stored on a single page. We must be able to navigate to different pages in the website in order to get more quotes.
Notice that the url for each new page contains a changing value:
Knowing this we can create a simple list of URLs to iterate through in order to access different pages in the website:
urls=[f”http://quotes.toscrape.com/page/{i}/“ for i in range(1,11)]urls
This returns a list of websites we can use:

From this list, we can create another “for” loop to collect the necessary number of quotes and their respective authors.
Avoiding Web Scraping Detection
One important thing to note: some websites do not approve of web scraping. These sites will implement ways to detect if you are using a web scraping tool such as Beautiful Soup. For example, a website can detect if a large number requests were made in a short amount of time, which is what we are doing here. In order to potentially avoid detection, we can randomize our request rate to closely mimic human interaction. Here is how we do that:
Generate a list of values:
rate = [i/10 for i in range(10)]
Then at the end of every loop, input the following piece of code:
time.sleep(random.choice(rate))
Here we are randomly choosing a value from the list we created and waiting that selected amount of time before the loop begins again. This will slow down our code but will help us avoid detection.
Bringing it all Together
Now that we have all the pieces, we can construct the final “for” loop that will gather at least 52 quotes and their respective authors:
The Entire Code to Retrieve at least 52 Quotes and their Authors
Once we run the code above we will end up with a list of quotes and a list of authors. However, our customer wants the quotes in a spreadsheet. To accommodate that request, we will have to use the Python library: Pandas.
Inputting the lists into a Pandas DataFrame is very simple:
# Creating a DataFrame to store our newly scraped information
df = pd.DataFrame()# Storing the quotes and authors in their respective columns
df[‘Authors’] = authorsdf[‘Quotes’] = quotes
Since the quotes and the authors were scraped in order, they will be easy to input into the DataFrame.
Once we have finished and ran the code above, the final DF will look like so:

Excellent! The DF looks great and is in the exact format requested from the customer. We can then save the DF as an excel spreadsheet file which we can then send to our customer.
Closing
We hope you learned a little bit about web scraping from this step-by-step tutorial. Even though the example we used may be quite simple, the techniques used will still be applicable to many different websites all over the internet. More complex looking websites that require extensive user interaction will require another Python library called Selenium. However, most websites will only need BeautifulSoup to scrape data. The walkthrough we have done here should be enough to get you started. Happy scraping!